Branching is easy. Merging is hard.
Forking a language model conversation requires only copying the KV cache. One branch explores cats, another dogs; one branch praises the mayor, another criticizes. But rejoining divergent branches has no standard mechanism. The options — pick a winner, summarize both, concatenate — all operate in token space. None performs reconciliation in the model’s own representational space.
This post tests a direct alternative: merge branches by interpolating their key-value caches.
For autoregressive transformers, the KV cache is the latent state. Run a shared prefix, save the cache at the fork, continue with two branch prompts, compute the suffix deltas, interpolate, decode.
This should fail. The branches traverse different semantic trajectories. Their keys and values occupy identical positional slots but represent different tokens. Averaging them could produce gibberish.
It does not. The merged cache decodes fluently in every case tested. But fluency is not the finding.
The finding is that merged states fall into three semantic regimes, and the boundaries between those regimes reveal structure in how transformers encode branch-specific information.
Code and figures live in the project repository.
Method
Run a shared prefix through the model. Save the KV cache at that point: the fork. Continue from the fork with two branch prompts, A and B, of equal token length. Save each branch’s cache.
Branch caches cannot be compared directly because the sequence length grows. The useful object is the suffix delta: the new keys and values added after the fork position.
delta_A = branch_cache_A[fork_position:]
delta_B = branch_cache_B[fork_position:]
The merge operator interpolates these suffix deltas and reattaches them to the shared fork:
merged_suffix = interpolate(delta_A, delta_B)
merged_cache = concat(fork_cache, merged_suffix)
Decoding from the merged cache requires a probe token (HuggingFace causal models need at least one input token to produce logits from a cache state). Metrics are averaged across four probe tokens (" The", ".", " about", " It") to reduce probe sensitivity.
Figure 1: Method Pipeline
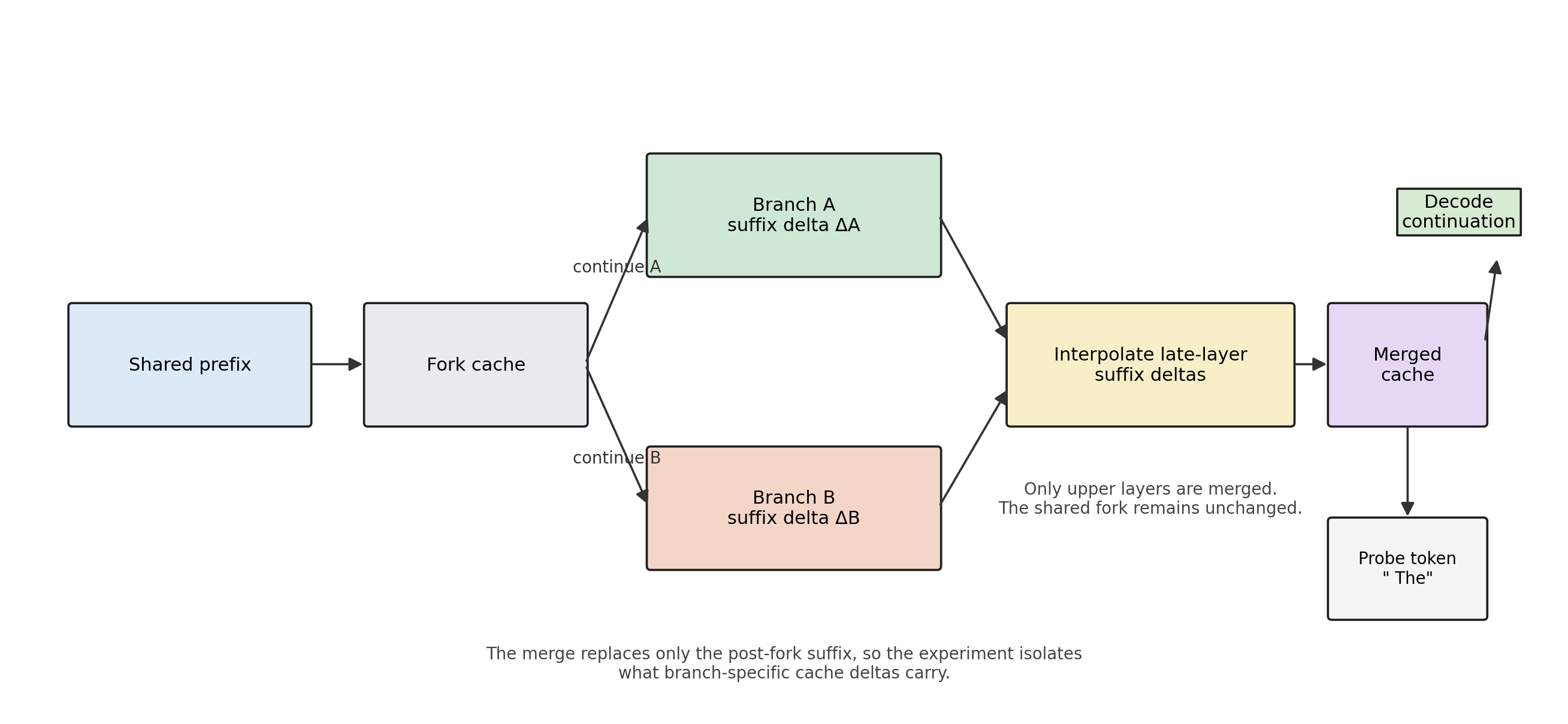
A shared prefix anchors both branches. The merge replaces only the post-fork suffix, isolating what branch-specific cache deltas carry.
Merge strategies
The experiments tested 23 merge strategies across four families.
Layer-level strategies apply a per-layer blend weight: uniform averaging, uniform slerp, late-only (upper half of layers), early-only, sigmoid ramp, and last-layer-only.
Head-level strategies operate per attention head: cosine-gated merging (merge only heads where branch similarity exceeds a threshold), max-norm head selection, norm-weighted slerp, sparse interleaved merging, cumulative merging, odd/even head merging, and orthogonal injection.
Component-selective strategies separate keys from values: V-only merging (merge values, keep keys from one branch), cross-wired K/V (keys from A, values from B), and alignment-gated V merging.
Weight search strategies evaluate multiple blend weights per pair (0.3, 0.4, 0.5, 0.6, 0.7) and select the weight that minimizes branch imbalance while maintaining sufficient branch mass.
Slerp (spherical linear interpolation) interpolates direction on the unit hypersphere and linearly interpolates magnitude. When vectors are nearly parallel, it falls back to linear interpolation.
Three regimes
The merged cache does not produce one kind of outcome. It produces three.
Three quantities separate them.
Branch balance measures which branch dominates the merged distribution:
balance = log(mass_A / mass_B)
where mass is the total probability on branch-specific discriminative tokens.
Branch mass measures how much probability remains on branch-specific vocabulary:
branch_mass = mass_A + mass_B
Entropy change measures whether the merge sharpens or diffuses relative to the unmerged branches:
dH = H(merged) - 0.5 * (H(branch_A) + H(branch_B))
Confluence occurs when balance stays near zero, branch mass stays high, and entropy remains stable. Both branches remain active.
Washout occurs when branch mass drops and entropy increases. The merge stays fluent but loses branch-specific content. Output drifts toward generic continuation.
Collapse occurs when branch mass stays high, balance shifts toward one branch, and entropy decreases. The merge sharpens into one branch and suppresses the other.
Figure 2: Regime Map
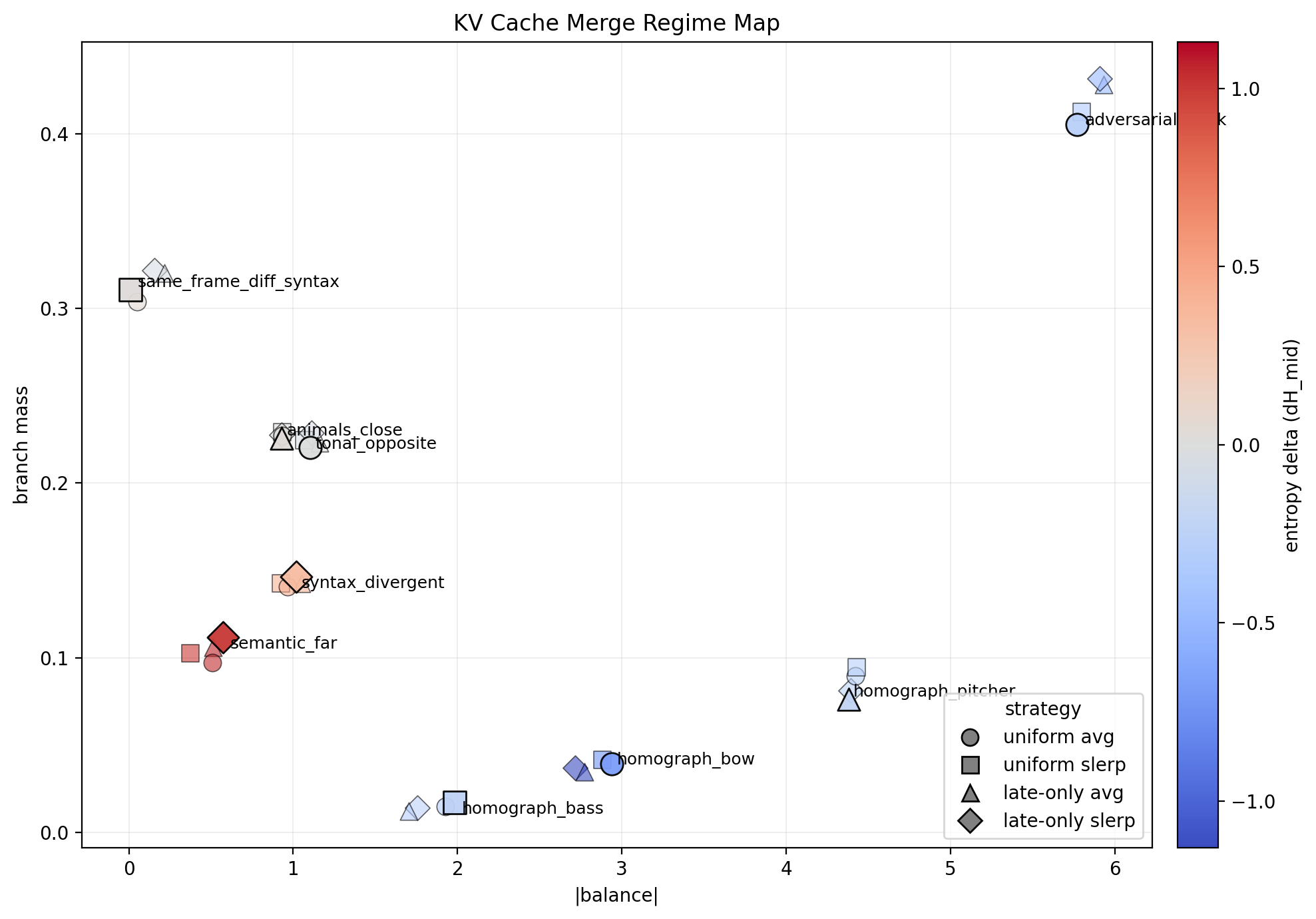
KV-cache merge outcomes in (|balance|, branch_mass) space, colored by entropy change. Three regimes emerge: confluence at low |balance| and high branch mass, washout at low branch mass with positive entropy change, and collapse at high |balance| with negative entropy change.
Confluence is real. Some pairs remain centered and retain branch mass after merging. Confluence is also not the default. Different-frame pairs wash out. Homograph and adversarial pairs collapse. Entropy alone cannot separate these failure modes — washout diffuses, collapse resolves. They fail in opposite directions.
What merges and what does not
The experiment battery comprised 267 branch pairs across 16 linguistic categories, tested on three models (distilgpt2, gpt2, gpt2-medium) with 23 merge strategies. The regime each pair enters is predicted by its linguistic category.
Merge-compatible alternations
Adjective-order swaps merge cleanly. “The dry dead trees” and “the dead dry trees” produce confluence: reordering modifiers does not disrupt the semantic trajectory.
Function-word substitutions merge. “Damage to the buildings” and “damage for the buildings” retain both branches. Low-information function words do not drive enough divergence to prevent confluence.
Adverb placement merges. “Completely destroyed the town” and “destroyed the town completely” produce confluence. Positional variation within the same semantic frame is reconcilable.
Quantifier swaps produce good balance. “Most residents” and “many residents” achieve low |balance| (0.259). Quantifiers modulate scope rather than introduce new semantic content.
Complementizer drop merges. “Officials said that the damage” and “officials said the damage” produce confluence. The presence or absence of “that” leaves the semantic frame intact.
Merge-incompatible alternations
Homographs collapse without exception. Bank (river/financial), pitcher (baseball/container), spring (season/coil), crane (bird/machine), bow (weapon/ship), bark (tree/dog), seal (animal/stamp), bass (fish/music) — all ten homograph pairs collapsed across all strategies and all models. Interpolation forces sense resolution; it does not maintain ambiguity.
Compound-noun swaps collapse. “Riverbank” and “sandbank” encode different referents. Replacing nouns alters the branch trajectory beyond the merge-compatible range.
Verb synonyms collapse. “Destroyed” and “demolished” appear semantically close but occupy different regions of the value cache. Synonym substitution exceeds the composable subspace.
Preposition swaps that encode relational structure collapse. Unlike function words, prepositions that change argument structure alter the frame.
Variable alternations
Dative alternation, reporting clause inversion, passive voice, and same-frame opposite valence pairs fall into different regimes depending on strategy, prefix length, and model. These categories occupy the boundary between merge-compatible and merge-incompatible territory.
Long shared prefixes increase confluence probability. More shared state produces smaller deltas, and smaller deltas are easier to interpolate.
Late-layer alignment predicts washout
Figure 3: Late V Alignment vs Entropy
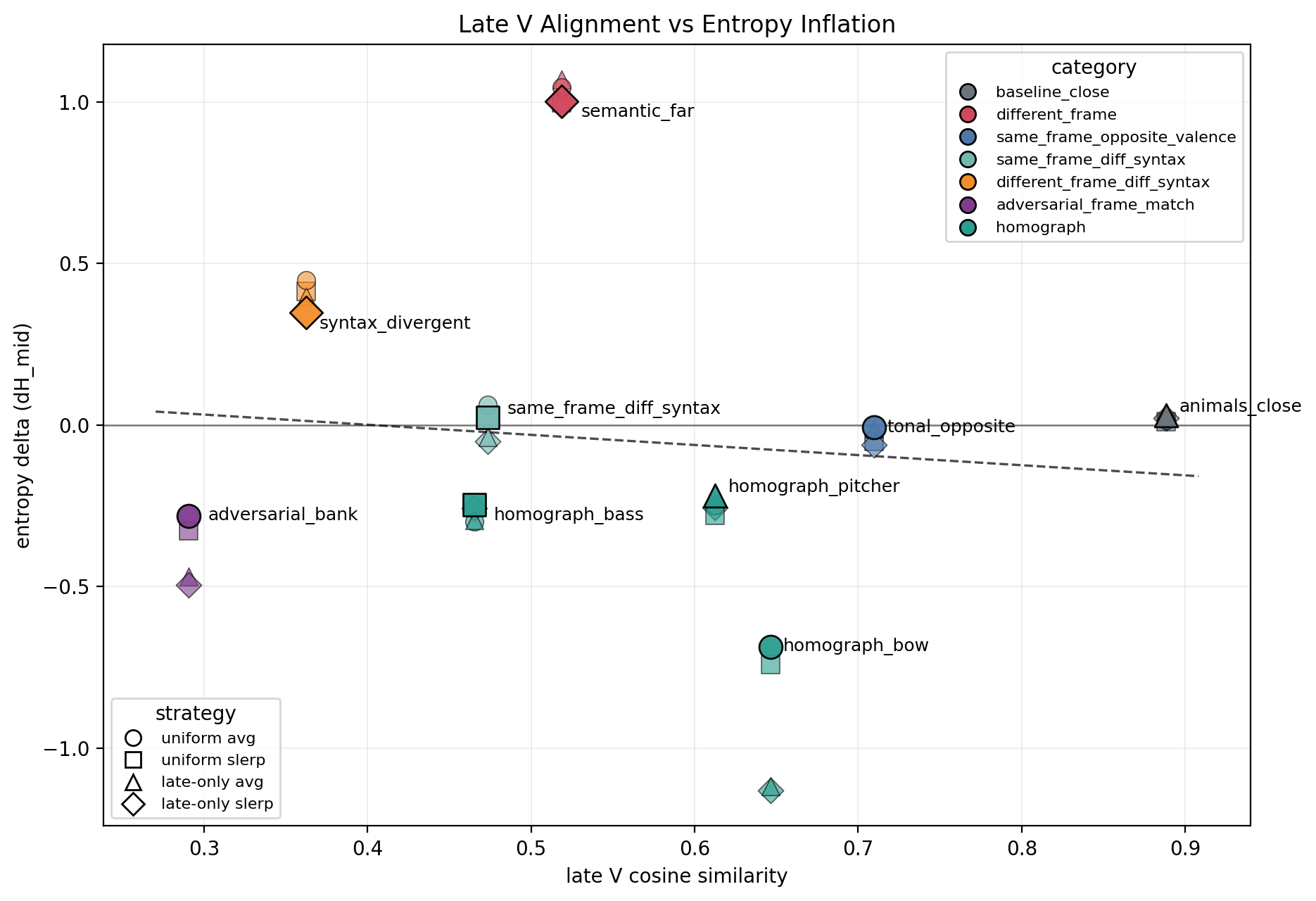
The strongest predictor of merge outcome is late-layer value-cache cosine similarity. High late-V alignment predicts stable entropy. Low alignment predicts washout.
But late-V similarity alone cannot distinguish confluence from collapse. Both produce stable or reduced entropy — confluence by preserving both branches, collapse by sharpening to one. The branch-balance metric is required to separate these outcomes.
A practical mergeability gate therefore requires two signals: late-V cosine to predict washout risk, and a trial-merge balance check to detect collapse.
Values are more composable than keys
The most consistent finding across all three models: merging values alone outperforms merging both keys and values.
In a transformer attention layer, keys determine what to attend to and values determine what to retrieve. Merging keys from two branches creates conflicting attention routing — the model attempts to attend to both patterns simultaneously, producing incoherent attention weights. Merging values while preserving one branch’s keys maintains coherent attention but blends the retrieved content. The query structure remains valid even when the returned content is a mixture.
Cross-component experiments confirm this dissociation. Using keys from branch A with values from branch B produces coherent but shifted outputs: the model attends according to A’s routing but retrieves B’s content.
This dissociation also explains merge asymmetry. Late-only strategies are not symmetric: A-anchored merging (A’s keys, interpolated values) produces different results from B-anchored merging (B’s keys, interpolated values). The anchor branch’s keys bias the merge outcome.
The scaling wall
Under fixed-weight strategies, gpt2 (12 layers) produces zero confluences. Every pair washes out or collapses. Two independent experimental runs confirmed this result.
The cause is geometric. The compatible subspace for merging narrows with depth. A fixed blend weight of 0.5 overshoots the merge for deeper models, where late layers carry more specialized representations.
Two techniques partially recover mergeability:
Per-layer weight search. Evaluating blend weights in {0.3, 0.4, 0.5, 0.6, 0.7} and selecting the weight that minimizes |balance| while maintaining sufficient branch mass recovers a 15% confluence rate on gpt2.
Per-head cosine-gated V-only merging. Measuring cosine similarity per attention head and merging only heads where value similarity exceeds 0.7 avoids corrupting incompatible heads. Combined with weight search, this achieves a 20% confluence rate on both gpt2 and gpt2-medium (24 layers, 345M parameters).
The scaling wall is not a hard boundary. It is a narrowing passage. Each layer of depth demands another degree of selectivity: per-layer weights instead of uniform blending, per-head gating instead of whole-layer merging, V-only instead of full K+V. This progressive narrowing is consistent with the residual stream view of transformers — each layer adds increasingly specific features, and interpolating task-specific representations requires more precision than interpolating general features.
Homograph impossibility
Homograph collapse deserves separate attention because the result is clean and the implications are clear.
Ten homograph pairs were tested across 23 strategies and three models. None produced confluence.
Homograph resolution writes sense-specific programs into the KV cache. The financial-bank program and the river-bank program cannot coexist in a single cache state because they require incompatible attention patterns in the same heads. Interpolation does not create superposition. It selects a winner — whichever sense has greater activation magnitude in the late layers.
One partial exception: the homograph “spring” confluenced on gpt2-medium using V-only late slerp with searched weights. This suggests that deeper models may separate sense-specific information into different heads, making selective head merging occasionally viable even for homographs. But one case in thirty does not overturn the pattern.
Cache merging cannot maintain unresolved lexical ambiguity. It can blend compatible frames. It cannot reconcile incompatible ones.
What this reveals about transformer representations
These experiments treat cache interpolation as a probe, not a tool.
Value representations occupy a partially linear subspace. Within that subspace, interpolation produces meaningful blends. Outside it, interpolation produces noise (washout) or winner-take-all dynamics (collapse). The subspace is wide enough to accommodate syntactic rearrangements but too narrow for semantic substitutions.
This subspace narrows with model depth. Distilgpt2 (6 layers) tolerates a fixed 0.5 blend weight. Gpt2 (12 layers) requires per-layer weight tuning. Gpt2-medium (24 layers) requires per-head gating. Each additional layer of depth adds representational specificity that interpolation must respect.
The linguistic taxonomy of mergeability tracks semantic distance, not syntactic distance. Adjective reordering, function-word substitution, and adverb placement are syntactically different operations. They all merge. Verb synonymy and compound-noun substitution are also syntactically different operations. They all collapse. The determining factor is whether the alternation changes the semantic trajectory — the sequence of latent programs that the cache encodes — or merely rearranges surface structure within the same trajectory.
Limitations
- Only GPT-2 family models were tested. Architectures with grouped-query attention, rotary positional encodings, or different training distributions may behave differently.
- Branch prompts must have equal token length, a constraint of the delta construction that restricts the naturalness of some pairs.
- The pair battery was constructed by AI agents optimizing for coverage. Category balance is uneven.
- Weight search over five discrete values is coarse. Continuous optimization might recover additional confluences at the cost of per-pair overfitting.
- Multi-probe averaging reduces but does not eliminate sensitivity to probe token choice.
Practical implications
KV cache merging is unlikely to become a production technique for reconciling divergent branches. The compatible subspace is too narrow, weight optimization is per-pair, and the method fails on semantically incompatible branches.
The mergeability signal itself has potential uses. Head-level cosine similarity between draft branches could predict which speculative decoding drafts are safe to merge. Models where more heads pass the cosine gate across diverse branch pairs have more separable representations — a measurable form of disentanglement. The merge outcome taxonomy provides a test for whether cache compression schemes preserve branch-specific information.
Conclusion
KV-cache interpolation is mechanically viable. The merged cache decodes fluently. But the semantic outcome depends on branch structure.
Syntactic rearrangements merge. Semantic substitutions wash out or collapse. Homographs are unresolvable. Model depth narrows the compatible subspace, but per-head gated value-only merging with weight search partially recovers mergeability through gpt2-medium (24 layers).
The question is not whether cache merging works. It works mechanically. The question is when it preserves meaning, when it dilutes it, and when it resolves it by force.
These experiments map a boundary in transformer representational geometry: the boundary between linearly composable and non-composable latent states. That boundary tracks semantic distance, narrows with depth, and runs through the value cache more than the key cache. Whether that boundary can be widened — by training or by architecture — is an open question. These experiments establish where it currently lies.
Acknowledgments
The experimental battery was developed through an autonomous research loop. Three AI agents — Claude, GPT/Codex, and Gemini — independently iterated on the experiment design. Claude built the initial linguistic taxonomy and pair battery. GPT proved the homograph impossibility result and discovered merge asymmetry. Gemini cracked the scaling wall with per-head gated merging and weight search.